FetchXML – The hidden gem of Flow

Have you ever wondered what this mysterious FetchXML Query feature of Dataversen List rows is?
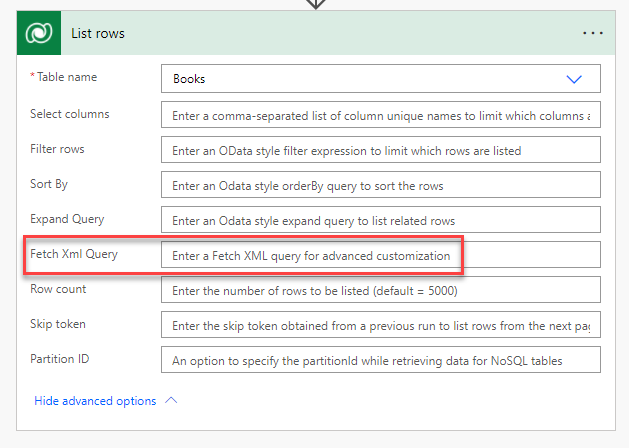
If you come from the world of Dynamics 365, you are probably familiar with this. Otherwise, you’ve probably never heard of FetchXML.
If you work with Dataverse (or Dataverse for Teams), you should. Namely, FetchXML is an easy and powerful way to make complex queries to Data.
Let’s get to know it with an example.
Example – Books and their loans
As an example let’s use the borrowing of books familiar to us from a previous post.
Our data model is simple. We have books with an author and 0-n bookings.

Let’s get started.
Searching for a field value behind a relation
Let’s imagine a situation where we use Flow to deal with books added last year (Books). We get the books first and then we do something for them. This time, we need (for a reason I haven’t figured out yet) the Date of Birth of the author of the book. The value is located in another table (Booking) to which there is a relation from the Books table.
This is probably the most common solution.

The problem, of course, is that we make an extra Power Platform service request (Get a row by ID – Author) for each book.
We can solve this by using the Expand Query feature (see example), but the easiest way to do this is by using Fetch XML.
Let’s open a model-driven app and use it to examine the books and their bookings. The Advanced Find function can be found at the top right.
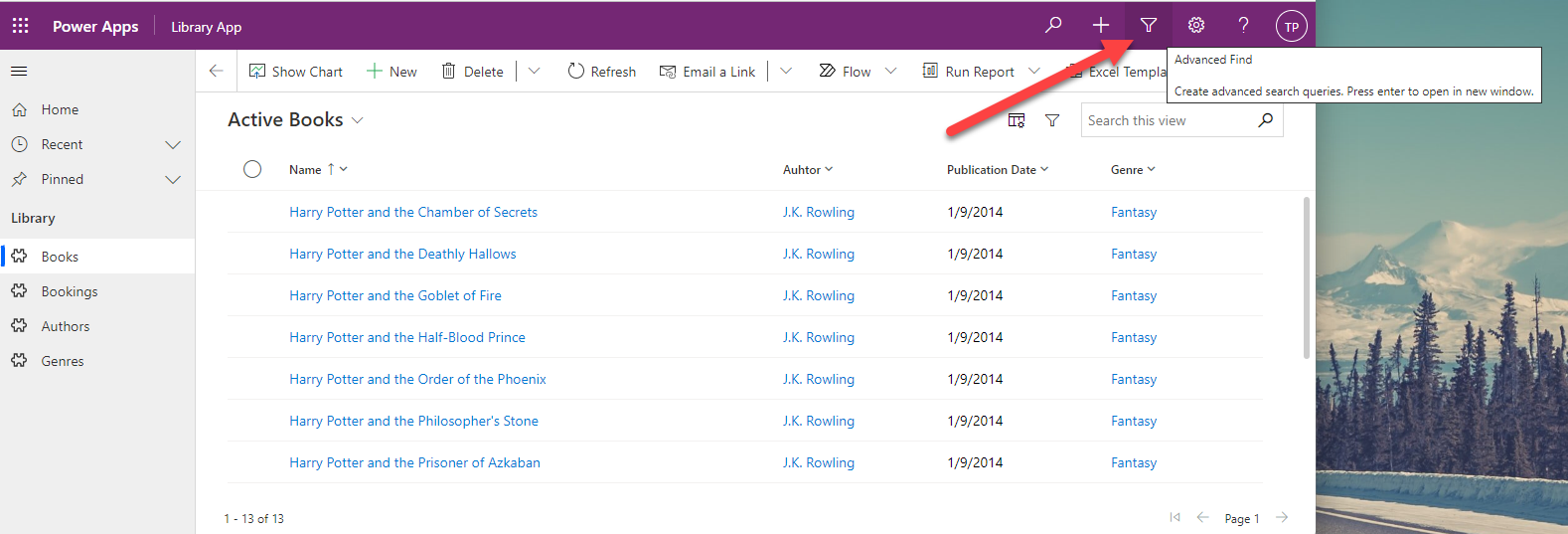
Let’s create a search that returns the books added last year.
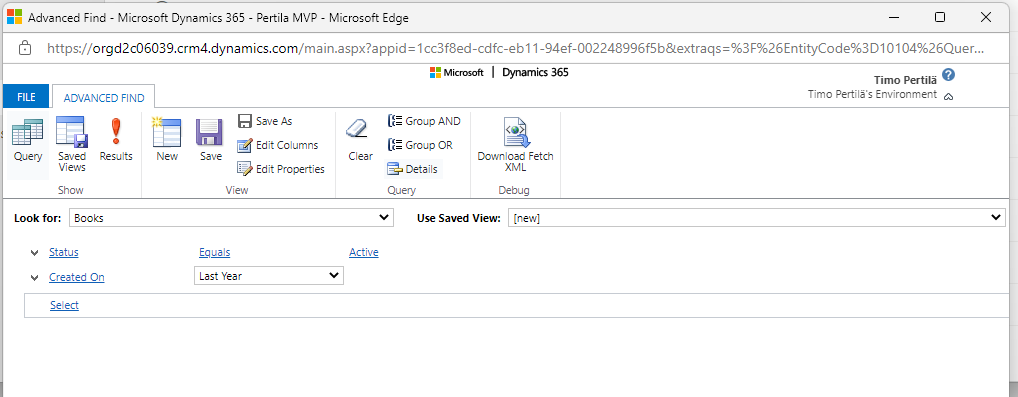
Add the desired fields (Edit Columns) to the search result.
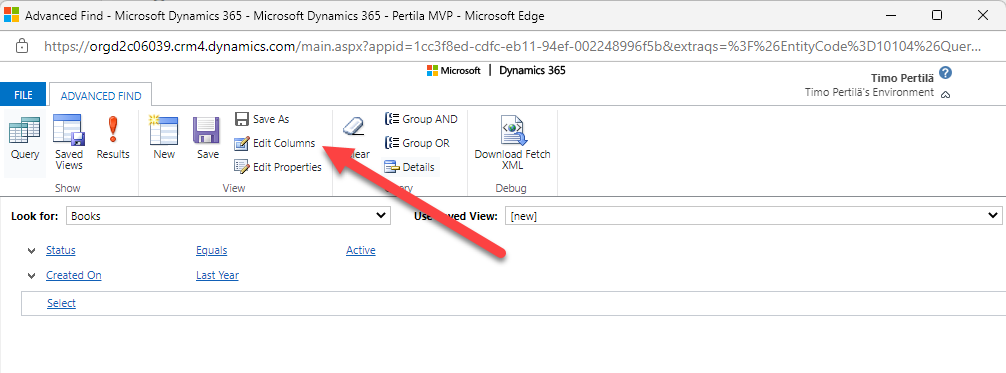
In the dialog that opens, select Add Columns.
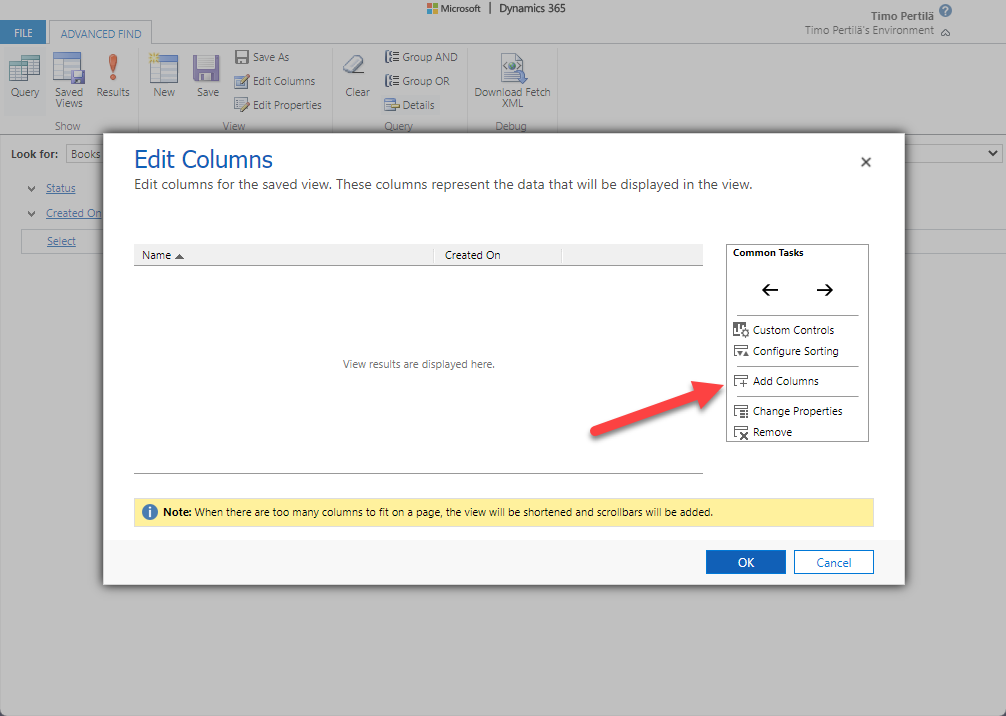
Change the table (Record Type) to Author and extract the Date of Birth field.
Press Results to test the query.

Now we have a search that returns both the name of the book and the date of birth of its author.

Of course, you can add all the fields you need in the search result.
However, the real magic lies in the last icon in the search editor. You can download the query you created in FetchXML format!

The downloaded query looks like this.
<fetch version="1.0" output-format="xml-platform" mapping="logical" distinct="false">
<entity name="tp_book">
<attribute name="tp_bookid" />
<attribute name="tp_name" />
<attribute name="createdon" />
<order attribute="tp_name" descending="false" />
<filter type="and">
<condition attribute="statecode" operator="eq" value="0" />
<condition attribute="createdon" operator="last-year" />
</filter>
<link-entity name="tp_author" from="tp_authorid" to="tp_auhtor" visible="false" link-type="outer" alias="a_e8cd14ea7dfbeb1194ef000d3ade7d82">
<attribute name="tp_dateofbirth" />
</link-entity>
</entity>
</fetch>The syntax is simple. It’s easy to add missing fields yourself, edit filter criteria, and more.
And best of all, you can use this in a Flow’s List rows action!

This way, we have the date of birth of the author we need available on Flow without any additional search.

Very effective!
But this will only get better…
Calculation of sums and figures (aggregation)
We know the number of pages in each book (tp_pages). How do we determine the average of the pages in a set of books?
The traditional approach would be as follows.
- List all books
- Go through the books and add the number of pages for each book to the variable (page count total)
- Finally, calculate the average of the pages (page count total divided by the number of books)

Obviously this does work, but it’s also unnecessarily slow for larger groups and it uses a lot of Power Platform service requests.
It’s smarter to perform the calculations in Dataverse. That too is possible with FetchXML. This time we have to write the xml by hand.
- add to the top: aggregate = “true”
- define an attribute with a computational value (tp_pages)
- define the type of calculation to perform (sum, avg, min, max, count)
The required snippet looks like this.
<fetch version="1.0" output-format="xml-platform" mapping="logical" distinct="false" aggregate="true">
<entity name="tp_book">
<filter type="and">
<condition attribute="statecode" operator="eq" value="0" />
</filter>
<attribute name="tp_pages" aggregate="avg" alias="AveragePageCount"/>
</entity>
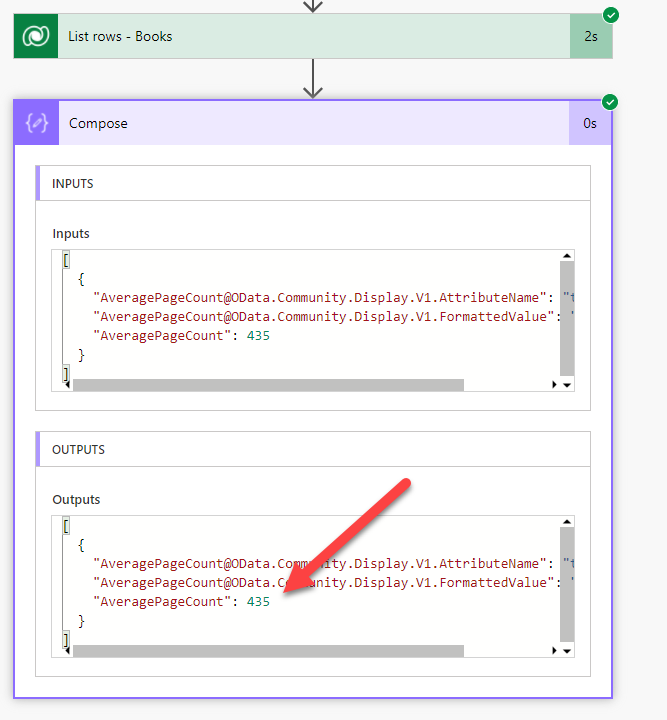
</fetch>And the whole thing is handled in Flow with one function.

And it works!
Rows without any relation
Lastly, let’s go through an example that I wouldn’t even try to do without FetchXML.
Our Booking table has a Lookup field to the Book table. It tells you which book the booking is related to. So how do we get to know all the books that have never been borrowed? That is, books that do not have any rows in the Bookings table.
We’ll use the Advanced Find function to create a query that returns all books that do not have a Bookings row associated with them.
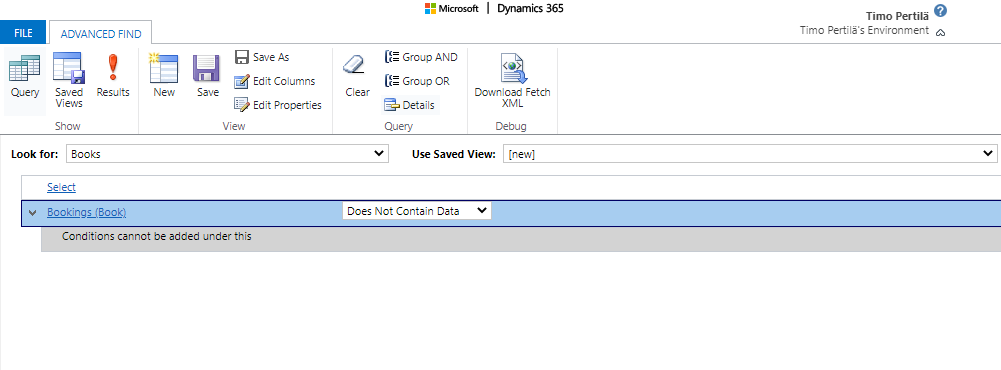
The downloaded FetchXML looks like this.
<fetch version="1.0" output-format="xml-platform" mapping="logical" distinct="true">
<entity name="tp_book">
<attribute name="tp_bookid" />
<attribute name="tp_name" />
<order attribute="tp_name" descending="false" />
<link-entity name="tp_booking" from="tp_book" to="tp_bookid" link-type="outer" alias="ak" />
<filter type="and">
<condition entityname="ak" attribute="tp_book" operator="null" />
</filter>
</entity>
</fetch>This can be used as in the previous examples in Flow.
Similarly, for example, you can search for all Accounts that do not have any contacts associated with them.
Summary
FetchXML is a great tool for working with Dataverse and Flow. For most queries, you can quickly create the body using the Advanced Find function. After that, you just edit the search criteria inside the Fetch XML to your liking in the Flow.
Aggregation sentences have to be written by themselves, but they also get to the grain quickly.
The end result is often a significant improvement in performance. Fewer functions, fewer Power Platform requests, and faster Flow execution.
However, keep in mind that when using FetchXML, the Flow function returns a maximum of 5000 lines. If you need more, you have to build the paging by yourself.
Many thanks for this Timo, I hadn’t thought of using aggregation!
Would it have been worth mentioning FetchXML Builder, especially as the new unified UI advanced find doesn’t currently include an option to download the FetchXML?
Yes, XrmToolBox and FetchXML Builder are superb! But I really hope that we can download FetchXML from the model-driven app UI also. Just like before.
Have you figured a way to get past the fact power automate does not page fetch queries and will only return top 5000 whereas list rows can be set to get 100,000? Or has that been fixed?
In that case I thonk you still need to build your own paging.
Like here: https://dreamingincrm.com/2021/06/26/paging-while-using-fetchxml-in-dataverse-connector/